



Azonnal elérhető hardver és szoftver használata a gépi tanulással való ismerkedéshez
 A gépi tanulás (GT) hardver és szoftver eszközeinek fejlődése kifinomult módszereket ígér a dolgok internete (IoT) élenjáró eszközei számára. A terület fejlődése miatt azonban a fejlesztők könnyen elmerülhetnek ezen technikák mögött lévő elméletek mélységeiben, így nem tudnak olyan – jelenleg is elérhető – megoldásokra koncentrálni, amellyel egy GT-alapú tervet a piacra juttathatnának.
A gépi tanulás (GT) hardver és szoftver eszközeinek fejlődése kifinomult módszereket ígér a dolgok internete (IoT) élenjáró eszközei számára. A terület fejlődése miatt azonban a fejlesztők könnyen elmerülhetnek ezen technikák mögött lévő elméletek mélységeiben, így nem tudnak olyan – jelenleg is elérhető – megoldásokra koncentrálni, amellyel egy GT-alapú tervet a piacra juttathatnának.
A gyorsabb haladást elősegítendő, ez a cikk röviden áttekinti a GT céljait és lehetőségeit, a gépi tanulási ciklust, és egy egyszerű, teljesen összekötött neurális hálózat, valamint egy konvolúciós neurális hálózat (CNN) architektúráját. Ezután a vezető irányzatot követő GT-alkalmazásokat támogató keretrendszereket, könyvtárakat és illesztőprogramokat tárgyalja.
Befejezésképpen megmutatja, hogy az általános célú processzorok és FPGA-k hogyan szolgálhatnak hardverplatformként a GT-algoritmusok implementálásának alapjául.

1. ábra Egy neurális hálózat egy bemeneti rétegből, egy vagy több rejtett transzformációs rétegből és a transzformáció eredményét jelentő kimeneti rétegből áll (Kép forrása: Digi-Key Electronics)
Bevezetés a gépi tanulásba (GT)
GT a mesterséges intelligencia (MI) részhalmazaként számos módszert és algoritmust tartalmaz. Az adatosztályozás az adatfolyamokban történő mintázatkeresés hatékony módszereként hamar magára vonta a figyelmet. A különféle problémák kezelésére algoritmusosztályok alakultak ki.
A klaszterező technikák és más nem felügyelt tanulási módszerek például különálló osztályok felismerésére alkalmasak nagy méretű adathalmazokban. A megerősítéses tanulás olyan módszereket kínál, amelyek feltárhatják az ismeretlen állapotokat és kiválaszthatják az alternatív megoldásokat azzal a céllal, hogy megtanulják felismerni a jövőben ezeket az állapotokat, és tudjanak megfelelően válaszolni is rájuk. Végül, a felügyelt tanulási módszerek a kívánt kimenetet reprezentáló, előkészített bemeneteket használnak az új bemeneti adatok osztályozási algoritmusának betanítására.
A felügyelt tanulási módszerek onnan kapták a nevüket, hogy a gondosan előkészített tanítási adathalmaz a bemeneti adatokat (nevük jellemzővektor vagy adatleíró-vektor) a várható kimenethez (nevük címke) párosítja, és ezáltal tanítanak be egy algoritmikus modellt a „címkézetlen” bemeneti adatok jövőbeni osztályozására. Tegyük fel például, hogy a fejlesztők munkája során egyes jellemzővektorok ipari folyamatok biztonságos feltételeit reprezentáló mintavételezett szenzorértékből állnak, más, saját mintákkal rendelkező jellemzővektorok pedig mind a nem biztonságos feltételeket reprezentálják.
A felügyelt tanulási módszerek ezeket a reprezentatív jellemzővektorokat plusz azok saját biztonságos/nem biztonságos címkéit használva taníthatnak be algoritmusokat a biztonságos és nem biztonságos feltételek új szenzorértékek alapján történő felismerésére.
Neurális hálózatok
A felügyelt tanulási módszerek között a neurális hálózati algoritmusok hamar elismertséget szereztek pontos adatosztályozási képességeik miatt. Egy egyszerűbb neurális hálózatnak három szakasza van (1. ábra). Az első egy bemeneti réteg, amely a bemeneti jellemzővektor egyes jellemzőinek bemeneteit tartalmazza. A második a neuronok rejtett rétege, amelyek ezeket a jellemzőket különböző módokon transzformálják. A harmadik réteg a kimeneti réteg, amely ennek a transzformációnak az eredményeit azon valószínűségek halmazaként mutatja, amelyek a bemeneti jellemzővektor-osztályba sorolhatók a tanítás során megadott címkék valamelyike szerint.
Emellett az egy rétegen belüli neuronok közötti összes kapcsolathoz és a következő rétegben lévő neuronokhoz súly (súlyzó tényező) tartozik, amely az adott kapcsolat relatív erősségét méri.
Egy teljesen összekötött neurális hálózatban minden i bemeneti neuronhoz tartozik xi jellemzőérték, amelyet egy olyan wij súlyozó tényező skáláz, amely a következő rejtett rétegben lévő összes aj célneuronhoz hozzá van rendelve. A rejtett réteg minden aj neuronja összegzi a w1jx1+w2jx2+…+wnjxn súlyozott bemeneteket [és eltolási (bias) értékeket], és ezután egy olyan aktivációs függvényt alkalmaz, amely skálázza, vagy egyéb módon ritkítja a kimenetéhez kapcsolt neuronok számára az összegzett eredményt. Ez a folyamat ismétlődik az egymást követő rejtett rétegeknél, és a végleges kimeneti rétegen a csökkentett érték annak a valószínűségét reprezentálja, hogy az (x1,x2,…xn) bemeneti jellemzővektor y1 vagy y2 címkeként osztályozható (az 1. ábrán látható egyszerű hálózat esetén).
A tanítási folyamat célja a modell finomítása a lehető legjobb eredmény érdekében a tanítási adathalmaz vektorai és a hozzájuk társított címkék között a súlyok és az eltolások (együttesen: modellparaméterek) igazítása révén. A tanítási algoritmus tipikusan egy véletlen modellparaméter-halmazzal indul, és a tanító algoritmus ezután ismételten átküldi a tanítási adathalmazt a modellen. A tanító algoritmus minden teljes átküldés után megpróbálja csökkenteni az előre jelzett és ismert címke közötti eltérést – vagyis a minden epochnál (teljes tanítási adathalmaz átküldésénél) valamilyen típusú veszteségfüggvénnyel kiszámolt eltérést.
A modellparaméterek függvényeként reprezentált veszteségfüggvény az e paraméterekkel társított többdimenziós térben egy felületet ad meg. Így egy jól hangolt tanítási folyamat lényegében a kezdőponttól (a modell random kezdeti paramétereitől) a többdimenziós paramétertérben a minimum ponthoz vezető leggyorsabb útvonal megtalálását jelenti (2. ábra).
Adott pontból a minimumpont felé történő változás iránya és sebessége bármely görbén természetesen a görbe érintőjének meredekségével, vagyis a deriváltjával (többdimenziós paramétertérben a parciális deriváltjával) írható le. Egy hipotetikus w paraméter és p és a többdimenziós felületen pozitív parciális derivált esetén például a paraméter a w = w-ap beállítással mozgatható a minimum felé, ahol a a tanulási sebesség, amellyel az olyan helyzetek kerülhetők el, ahol a p olyan nagy, hogy egyedül a w-p átugorhatja a minimumot, és sosem konvergál.
A neurális hálózatok tanítási algoritmusai ezt a gradiens módszernek nevezett technikát vagy variánsait használják minden epochban a veszteségfüggvény számítását követő modellparaméter-módosításokra. A minimumhoz vezető legrövidebb út egyes epochokban történő kiszámításával a tanítási algoritmus a minimális veszteséghez tartozó modellparamétereket fogja megtalálni, vagy a minimális veszteséghez egy annyira közelit, hogy a további epochokkal történő iterációk már csak kicsit módosítanának az eredményen.

2. ábra A neurális hálózat tanításának célja, hogy megtalálja a veszteségfüggvényt (a várt és számított kimenet közötti eltérést) minimalizáló paraméterhalmazt, amihez a minimális veszteségi ponthoz vezető legrövidebb út meghatározásának gradiens módszerét használja (Kép forrása: Mathworks)
Komplex neurális hálózatok
Ez az általános tanítási folyamat elvileg minden neurális hálózatra vonatkozik, akár az 1. ábrán látható egyszerű architektúrára emlékeztet, akár egy mély neurális hálózat (deep neural network, DNN) terve sok rejtett réteggel, vagy teljesen más architektúra. Konkrét alkalmazásaik kezeléséhez a fejlesztők számos neurális hálózati architektúrából válogathatnak. Közülük a CNN architektúra vált a képfelismerést használó alkalmazások kedvelt módszerévé.
A CNN architektúrát képek, kézírások és egyéb komplex reprezentációk magas szintű felismerését igénylő alkalmazásokhoz fejlesztették ki. Ez „pipeline”(csővezeték) megközelítést használ, amely megtanulja a bemeneten kapott fontos jellemzőket, és ezeket a kimeneten osztályozza (3. ábra).

3. ábra A CNN egy kép több receptív mezőn át történő szűrését végző transzformációkból álló jellemzőtanulási szakaszt kombinál egy osztályba sorolási szakasszal, amely ezeket az eredményeket végső kimeneti réteggé alakítja vissza (Kép forrása: Mathworks)
A CNN a kép előfeldolgozását végző bemeneti réteggel kezdődik. A jellemző tanulási szakasz általában több konvolúciós rétegből, korrigált lineáris egységből (Rectified Linear Unit, ReLU) és összevonó (pooling) függvényekből áll, amely utóbbiak azonosítják az éleket, színcsoportokat és a kép más jellegzetességeit.
Ehhez az azonosításhoz a konvolúciós réteg megvizsgálja a kép bemeneti térfogatát több olyan neuronhalmazzal (ezeket mélységoszlopnak nevezik), amelyek ugyanahhoz a lokális régióhoz (receptív mezőjükhöz) kapcsolódnak a bemeneti képben és fogadják minden színcsatornáját. A konvolúció elvégzéséhez ez a – szűrőnek vagy kernelnek (magnak) nevezett – neuronhalmaz elcsúsztatja receptív mezőjét a kép felett. A folyamat során a kernel a bemenetek korábban már leírt súlyozott összegét számítja ki. Ugyanígy, a ReLU réteg a korábban ismertetett aktivációs függvényként szolgál. Az összevonó réteg egy speciális függvényt tartalmaz, amely hatékonyan ritkítja a kapcsolt kernel által eredményként adott mintát.
A CNN végső, osztályozási szakasza újra összekapcsolja az egyedi kernelkimeneteket, és kimenetként kiszámítja annak valószínűségét, hogy a bemeneti kép megfelel-e a tanításnál használt valamelyik címkézett képnek.
A fejlesztők konkrét CNN architektúrákból válogathatnak, a viszonylag sekély eredeti LeNet, AlexNet és CIFAR ConvNet modelltől a nagyobb, 22 réteges GoogleNet architektúrán át az ImageNet adatbázist használó évente rendezett vizuális felismerési versenyben (ImageNet Large Scale Visual Recognition Competition) alkalmazott, több száz rétegű nagyon mély modellekig. Az ilyen DNN-ek olyan drámai nemlineráris transzformációkra képesek, amelyek a jellemző kivonásához és komplex képek nagyon alacsony hibaarányú osztályozásához szükségesek.
A CNN-ek megvalósításához azonban még a legutóbbi időkig is szükség volt a matematikai valószínűségszámítás, statisztika és lineáris algebra alapos ismeretére. Napjainkban a fejlesztők már támaszkodhatnak a hierarchikus szoftverkészletekre épült kifinomult gépi tanulási keretrendszerekre, ami lényegesen leegyszerűsíti a komplex neurális hálózatok, köztük a CNN-ek megvalósítását.
GT-keretrendszerek
A MATLAB for Machine Learning mellett a Cognitive Toolkit (Microsite), a TensorFlow (Google), a Veles (Samsung) és sok más keretrendszer biztosít erőforrást a neurális hálózati modellek tervezéséhez, tanításához és telepítéséhez. Ezeken a keretrendszereken belül a fejlesztők a Keras, a TensorFlow Estimators vagy más gépi tanulási könyvtárt használhatnak a neurális hálózati rétegek leírására és a tanítási algoritmusok implementálására. Ezek a könyvtárak viszont olyan optimalizált matematikai könyvtárakat használnak, mint például a gradiens útvonal és a veszteségfüggvények számításához szükséges komplex mátrixműveleteket kezelő NumPy. Ez utóbbi könyvtárak pedig az említett műveletekhez szükséges speciális numerikus számításokat a Basic Linear Algebra Subroutines (BLAS), vagy más alacsony szintű könyvtárra épülve végzik. A tanítás gyorsítása céljából ezek a környezetek nagy mértékben támaszkodnak egy vagy több grafikus processzorra (GPU) és a hozzájuk tartozó olyan GPU-támogatott könyvtárakra, mint amilyen a NumPy-kompatibilis CuPy, a BLAS-kompatibilis cuBLAS vagy az NVIDIA cég saját CUDA Deep Neural Network (cuDNN) könyvtára. Végül, ezek a különböző könyvtárak még alacsonyabb szintű illesztőprogramokat használnak, köztük a nyílt platformos Open CL-t és az NVIDIA CUDA GPU-támogató szoftverét.
A numerikus matematikai feldolgozásokat végző könyvtárak intenzív használata hűen tükrözi a mátrixműveletek neurális hálózatok fejlesztésében betöltött jelentős szerepét. Konkrétan egy gemm (general matrix multiply) nevű általános mátrix-szorzási művelet dominál általában a neurális hálózatokban és ezen belül a CNN-ekben használt számítások terén (4. ábra).

4. ábra Bár különböző befolyása van az eltérő CNN-architektúrákban, az SGEMM nevű egyszeres pontosságú lebegőpontos mátrix-szorzási művelet dominál a betanítási szakaszban és a végkövetkeztetésben (Kép forrása: Arm®)
A mátrixműveletek túlsúlyából adódóan a kiszolgáló hardvernek központi jelentősége van az adott neurális hálózat betanítási idejének és a kész modell döntési idejének meghatározásában. Ez gyakorlatban azt jelenti, hogy még egy olyan viszonylag alacsony szintű általános célú rendszer, mint amilyen a Raspberry Pi is használható a CNN-betanításra és konklúzióra, amennyiben a célalkalmazás mérsékelt teljesítményigényeket támaszt. Tény, hogy bármely, Arm® Cortex® mikrokontroller (MCU) és más általános célú processzor köré épült rendszer használható GT-platformként.
Az ARM egy olyan speciális számítási könyvtárral (Compute Library) támogatja a fejlesztőket abban, hogy saját Cortex® MCU-jain neurális hálózatokat telepítsenek, amely az Arm® Cortex®-A sorozatú MCU-kra, például a Texas Instruments Sitara MCU-kra, az NXP i.MX6 MCU-kra és az NXP i.MX8 MCU-kra optimalizált. Az Arm® Cortex®-M-alapú MCU-khoz az Arm egy CMSIS-NN nevű neurális hálózat-specifikus könyvtárat biztosít a Cortex Microcontroller Software Interface Standard (CMSIS) az Arm® Cortex®-M-sorozatú eszközökhöz (5. ábra). A Cortex Microcontroller Software Interface Standard (CMSIS) bővítményének tervezett CMSIS-NN konvolúciós rétegek, összevonás, aktiváció (pl. ReLU) számára optimalizált és a neurális hálózati modellekben gyakran használt más függvényekkel egészíti ki a CMSIS-CORE szoftvert.
A CMSIS-NN könyvtárral a fejlesztők például megvalósíthatják modelljüket egy STMicroelectronics Mbed-kompatibilis NUCLEO-F746ZG fejlesztői kártyán, amely Arm® Cortex®-M7-alapú STM32F746ZG mikrokontrollert használ.
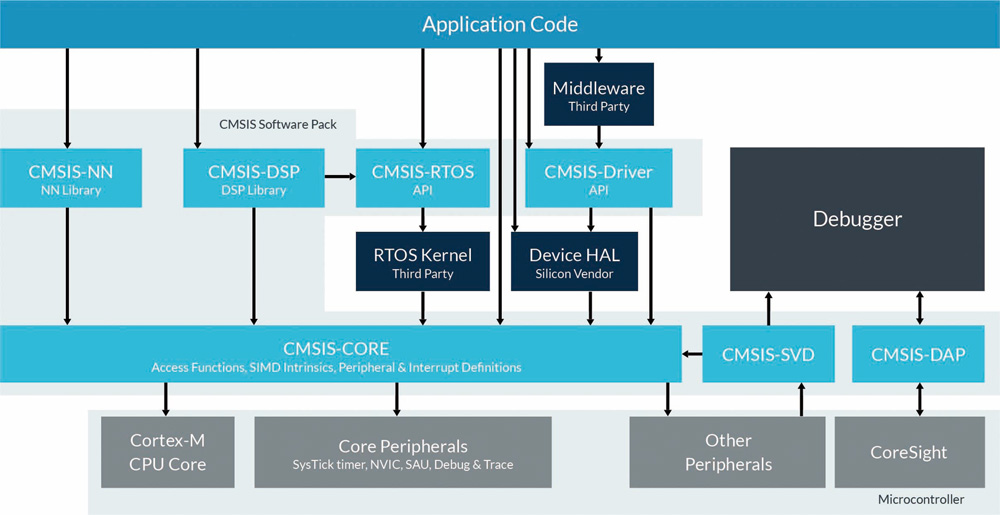
5. ábra A CMSIS-NN könyvtár a neurális hálózati modellekben gyakran használt függvényekkel egészíti ki a CMSIS-CORE szoftvert (Kép forrása: Arm®)
A speciális MI-processzorlapkák lényeges teljesítménynövekedést fognak biztosítani a neurális hálózatok és más gépi tanulási algoritmusok számára, de ezek általában még a tervezés fázisában maradnak, amíg az algoritmus nem véglegesedik.
A fejlesztők fokozott teljesítményigényükkel az azonnal elérhető FPGA-k, például az Intel Arria 10 GX, a Lattice Semiconductor iCE40 UltraPlus vagy az ECP5 áramkörök felé fordulhatnak.
Ez az FPGA osztály digitális jelfeldolgozó blokkokkal gyorsítja a GEMM műveleteket, és beágyazott memóriablokkjaival csökkenti az ilyen számításigényes műveletek teljesítményét korlátozó szűk memóriaelérési keresztmetszeteket.
A Lattice Semiconductor tovább is lépett az FPGA-alapú modellek területén saját fejlesztésű SensAI szoftverkészlettel, amely gépi tanulási FPGA IP-t és neurálishálózat-fordítóprogramot biztosít. A SensAI használatával a fejlesztők magas szintű neurális hálózatokat építhetnek az elérhető Lattice FPGA fejlesztői platformokon, köztük a Lattice ICE40UP5K-MDP-EVN mobilfejlesztési kártyáján és a Lattice LF-EVDK1-EVN beágyazott látásfejlesztő készletén.
Bár a gyorsabb hardverplatform általában rövidebb betanítási és konklúziós időket is jelent, a célplatform elérhető erőforrásainak korlátai miatt rendszerint gondos egyensúlyozásra van szükség a konklúziós idő, látencia, memóriahasználat és teljesítményfelvétel között. A gépi tanulás szakértői ezekre a követelményekre az egyes neurális hálózati architektúrák további finomításával válaszoltak. A modellparaméterek és aktivációs függvények csökkentett bitszámú kvantálásához hasonló módszerek a korábbi megközelítésekhez képest a memóriaigény 3-4-szeres csökkentését eredményezték. A további finomítások tovább csökkentik a modellek méretét és csökkentik a komplexitást a számítások rövidebb döntési időt és alacsonyabb látenciát biztosító gyorsítása és az alacsonyabb teljesítményfelvétel érdekében.
Az innovatív modellarchitektúrák, tanítási módszerek és a speciális hardverek kombinálása az élvonalhoz közelíti a gépi tanulási módszereket, és elérhetővé teszi bármely fejlesztő számára.
Következtetés
A gépi tanulás a felismerés, az objektumazonosítás és számos más, intelligens eszközökben igényelt funkció létrehozásának hatékony, fejlődő területe. Jóllehet korábban a gépi tanulási technikákat csak a MI-szakértők használhatták, a gépi tanulási keretrendszerek széles körű elérhetősége kitárta a kapukat a vezető irányzatot követő fejlesztők változatos alkalmazásai előtt.
A gépi tanulás lehetőségeinek folyamatos gyors fejlődése ellenére a fejlesztők máris használhatják ezeket a keretrendszereket az általános célú processzorokkal és mikrokontrollerekkel a gépi tanulást használó alkalmazások széles körének fejlesztéséhez.
Szerző: Rich Miron – Digi-Key Electronics
Digi-Key Electronics
Angol / német nyelvű kapcsolat
Hermann W. Reiter
Director, Global Strategic Business Development
Digi-Key Electronics Germany
Tel.: +49 151 6286 5934
E-mail: Ez az e-mail-cím a szpemrobotok elleni védelem alatt áll. Megtekintéséhez engedélyeznie kell a JavaScript használatát.
www.digikey.hu
Még több Digi-Key Electronics














